Serverless Strategies: Multi-Account Orchestration
This is the first article in a series on architectural design challenges in cloud computing. I titled the series 'Serverless Strategies', but these patterns could very well apply to container- and vm-based applications. I think cloud-native design strategies is a better title, but the CNCF popularized a definition more narrowly focused on containers and microservices.
Cloud systems are frequently organized into multiple 'accounts'. I use the AWS term here, but the construct is similar to GCP projects and Azure subscriptions or resource groups. Accounts can segregate resources, data and activity to isolate lifecycle environments (e.g. development, test, production), specific applications or customers, PHI vs non-PHI, regulated and unregulated, and so on.
Cloud systems often need maintenance, governance, audit or business domain-specific activity that spans these accounts. The activity could be anything from moving data between storage mediums or across accounts, to tagging or reconfiguring uncompliant resources, to reporting on suspicious user actions.
Here are some examples of small applications I recently created:
- Resource tagging: Correct tagging where possible and report on those needing human attention
- Resource inventory: Create a periodic report on resources by environment and type
- Configuration management: Synchronize AWS resource configurations to an external CMDB in near real-time
Regardless of the frequency and invocation style (scheduled or triggered by an event), orchestrating operations across multiple accounts requires some planning, coding and deployment effort outside of the core application purpose. We need to communicate with resources in accounts in a way that preserves least-privilege principle, is resource-efficient, meets latency expectations, can be deployed with IoC and code pipelines, and is ideally maintenance free.
In this article I review options for solving challenges and opportunities for:
- account locality
- account identification
- permissions
- region locality
The architectures depict the application as a cloud function (in AWS terms, a Lambda function), but the solutions are applicable to container-based, vm-based or other application platforms as well. These multi-account applications aren't usually core to the business, but are supporting players in keeping the organization's operations, security, technical systems healthy. Serverless platforms are a great choice for running these lightweight tasks. (Not to say that you can't build core applications on them as well).
1. Account Locality
First, in which accounts do we deploy the application?
Poor Solution: Account Distributed
We could deploy the application in every account, and perhaps in some cases, avoid all orchestration. Maybe that's ok for 4 accounts, but how about 100? Do you want to set up, maintain and pay for 100 code pipelines? How to you handle partial deployment failures, with application instances in different states. Do you need to recover or fix data? Do they all need to come on line together or are they independent? And how do you monitor and triage them? You need to aggregate the status, alerts and logs. In short, it's a lot of overhead.
Best Solution: Account Centralized
We want one application instance to manage and one code pipeline that deploys it. We can call this a hub-and-spoke solution. The account that hosts the application is the hub, and all other accounts are spokes. You don't need a special account for the application. Services on the hub account can also be a target of the application.
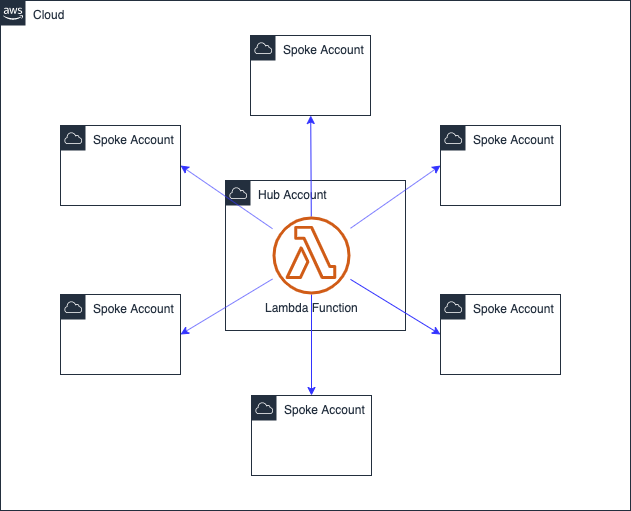
2. Account Identification
Second, the application needs to get a list of account identifiers. (In AWS, they are 12 digit numbers). We may need some grouping or ordering if the activity is to be performed on a subset or in a certain order.
OK Solution: Static Configuration
We statically configure the account ids in code (yikes!) or externally in a configuration file, a database (better) or an env parameter data store, like AWS SSM Parameter Store (best?). Now what happens when accounts are added or removed? Is notification within the organization flawless? You'll have to coordinate the application reconfiguration with the new or deleted account.
Possible Fix: Add an account event-based helper to update the configuration
Better Solution: Dynamic Discovery
We can query the AWS Organizations service for all accounts. If you need to operate on a subset or group or order the opeations, you can use the Organizational Unit (OU) construct or account or OU tags.
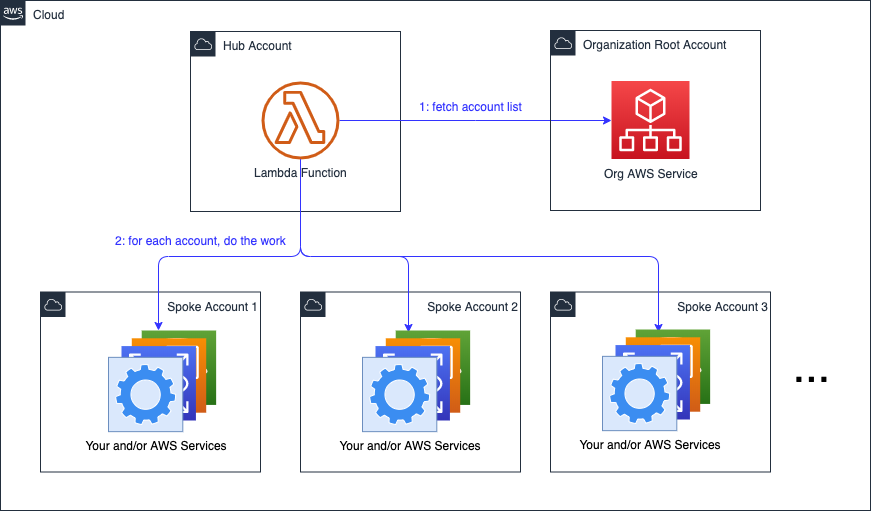
The root account is selected by the Enterprise. The account list is available from the AWS Organizations endpoint in the root account. (The endpoint serves the SDK clients which the application uses, as well as the CLI and console).
If your root account also is a target of the application, then it is also a spoke.
3. Permissions
Third, the application needs to access one or more services in many accounts. By default, no application can access anything, even the standard cloud services like Organizations, so we have to explicitly enable them through security policies and roles.
In AWS, when the client and service are in the same account, you can attach a security policy to just the client. But when they the client and service are in different accounts, the target service also needs an explicit permission for the specific client. The cross-account permission on the target services, in this case the root and spoke account services, can be done in two ways.
Poor Solution: Resource-based Permissions
Some resources, for example AWS S3 buckets and SQS queues, allow for direct permissions to non-local clients. In the case of a Lambda function, its ARN (a unique identifier) is referenced in the security policy.
On initial rollout, we need to add the permission to all the resources in all accounts, and maybe in an enhancement, add or remove more permissions. This can get messy fast.
We can use generally use Infrastructure as Code (IoC) mechanisms, e.g. CloudFormation, but only if the target was created with that tool. But what if those are in many CloudFormation 'stacks'? Lots of stacks to update on lots of accounts equals overhead. Maybe you can script those policy changes, but what if there are policies for other applications? Those scripts have to be smart and only change the relevant sections. More overhead.
Best Solution: Assume Cross-Account Roles
Create a role on each spoke, and the root, that has the required permissions to all services. The role explicitly grants the client, in this case the Lambda ARN, the ability to 'assume' it. We also add the assume role permission on the hub account's Lambda Execution Role.
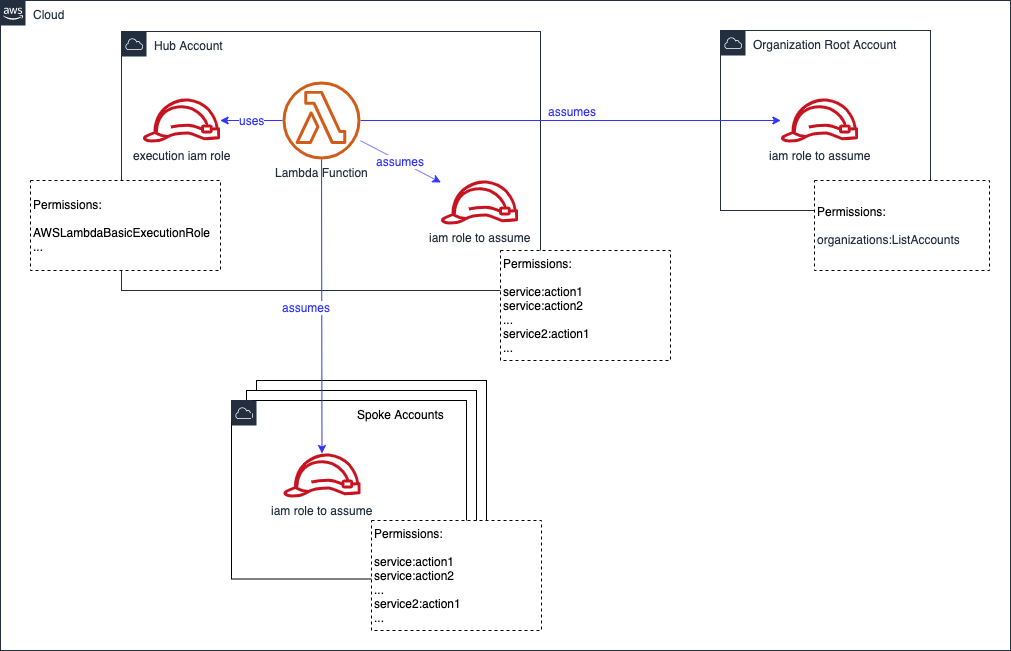
The Lambda core code might look something like this in python (simplified):
accounts = get_account_list()
for account in accounts:
role_arn = get_role_arn(account)
credentials = boto3.client("sts").assume_role(role_arn)
session = boto3.Session(credentials)
# Now do the operations, e.g. for s3:
s3_client = session.client("s3")
...
Now we can orchestrate deployment in two clean phases:
- deploy roles on spoke/root account
- deploy core hub account application
Create the assume roles in your favorite IoC tool's template, plan, recipe, etc., and deploy them on each spoke prior to your rollout (assuming permissions are only added). Better yet, write a script to run create or update-stack on every account or use the cloud-providers utility, e.g. AWS StackSets.
4. Region Locality
Finally, in which regions do we deploy if your business operates in multiple regions? I offer no winner. The answer is multi-factored and dependent on business-domain issues, cost, technical limitations, regulatory and security, or cloud-provider limitations.
Non-preferred Solution: Region Distributed
Your hand may be forced on this one to a distributed one.
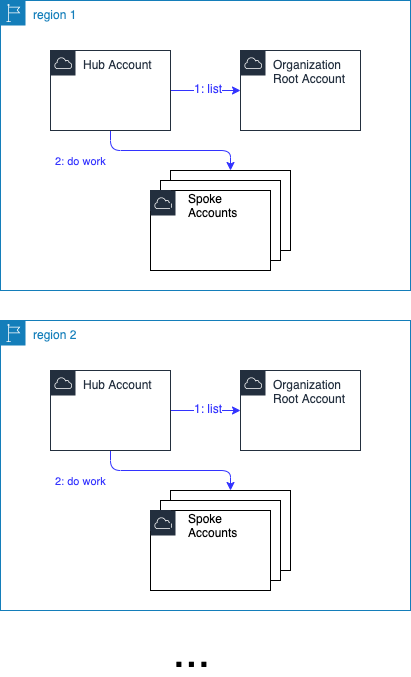
Some possible reasons driving this distribution:
-
Cloud-provider Limitation
In a previously referenced example, the CMDB synchronizer was triggered on CloudWatch events. Events may only be received by subscribers in the same region in which they originate. So I had to deploy the application in all regions in which the business operated. -
Data transfer costs and time
You may have large data sets. Pushing them across regions might cost you $.10/GB and add unacceptable latency. -
Regulatory policy
The national regulations may prohibit you moving data even temporarily across national boundaries.
Note that in AWS, 99% of the services have no interactions across regions. However, you can create an SDK sessions on another region and do your work.
Preferred Solution: Region Centralized
I prefer this because less stuff to manage is better.
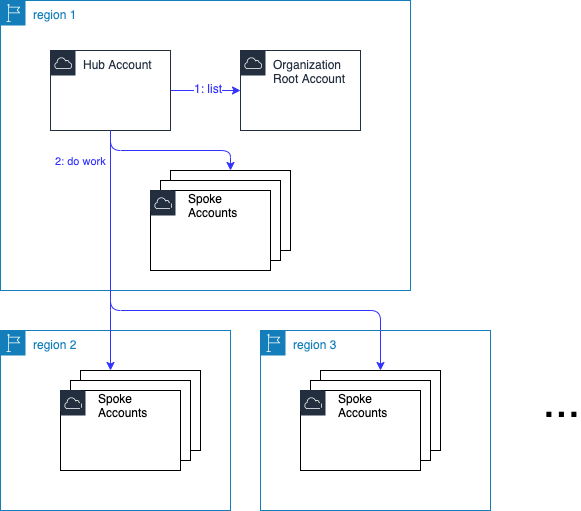
If your context allows this, then create a 'hub' region.
Non-Regional Cloud Services
A few cloud services, like AWS' Organizations and IAM services, are global services. Whatever you create on one region is available to all regions.
That's generally a good thing and makes life simpler. You can roll out assume roles to all accounts once, and they will work in all regions. Likewise you create the Lambda execution role once on some designated 'home' region. (In CloudFormation create a condition to check if the current region matches the home region, and attach the Condition to the role resource).
Conclusion
When a process needs to execute an operation spanning multiple
accounts or separately in many accounts, you have four significant
design challenges: account locality, account identification, permissions and region locality. My recommendation is to deploy on one account (hub and spoke), dynamically discover accounts, use role assumption and deploy in as few regions as possible.
Comments? email me - mark at sawers dot com